 2024-07-01
2024-07-01 阅读:6812
阅读:6812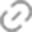 来源:曲速超为
来源:曲速超为AMD GPU的发展历程,可以说是一部跨越时代的传奇。从R600的诞生,到今天的CDNA3,每一次的迭代都标志着GPU技术的一次重大突破。让我们一起回顾这段激动人心的发展史,感受AMD GPU的魅力与力量。
在上期文章中梳理了NVIDIA这位‘老大哥’的GPU架构演进之路,两大巨头的GPU架构发展史,既是一部技术革新的历程,也是一部市场竞争的传奇。它们之间的竞争与合作,共同推动着GPU技术的不断进步,为我们带来了更加丰富多彩的数字世界。
2006年,AMD收购ATI,获得GPU技术,是当时唯一同时具备CPU和GPU设计能力的公司。
R600:AMD首款DirectX 10芯片
2007年,AMD-ATI发布了自己第一款支持DX10、SM4.0的显卡,名为Radeon HD 2900 XT,全新的R600架构,台积电80nm工艺制程,集成7.2亿个晶体管,核心面积408平方毫米,320个超标量流处理器,512-bit的显存位宽,最大超过128.5GB/s的显存带宽,全面支持DX10、SM4.0,AvivoHD视频硬件加速器等组件。
R600是将原有的4D矢量ALU扩展设计为5D ALU(准确叫5个1D ALU),每个ALU可以执行任意的1D+1D+1D+1D+1D或1D+4D或2D+3D的指令运算,所以这种架构也叫5D Superscalar超标量架构。
AMD称这些5D ALU为统一流处理器单元(SPU),每1个SPU中有5个ALU,4个ALU可以进行MADD操作,1个(可称SFU,特殊函数运算单元)可执行函数运算、浮点运算、Multiply运算,每个流处理器单元每个周期只能执行一条指令。
R600设计了320个流处理器(64个流处理器x5),分为4个SIMD阵列,每个SIMD阵列分为两组,每组包含40个流处理器(16个流处理器x5),4组纹理单元,每组包括4个纹理过滤单元、8个纹理寻址单元、20个纹理采样单元。
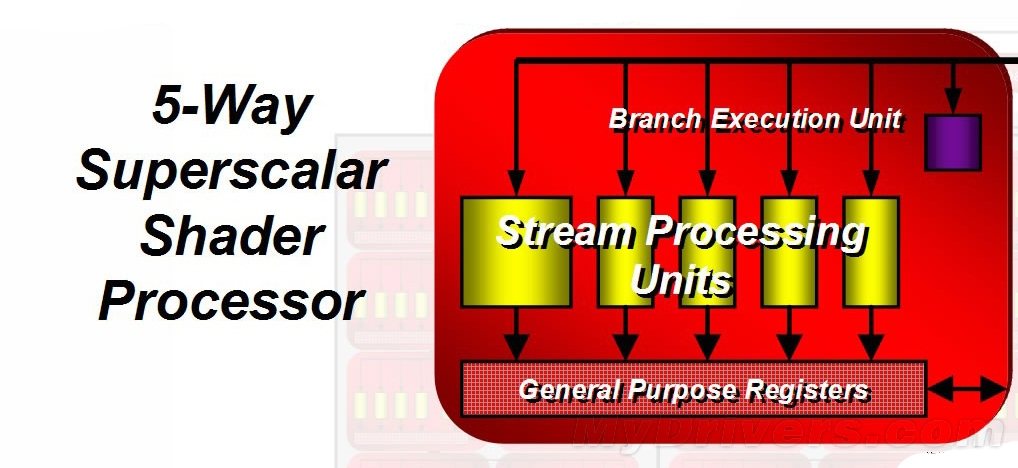
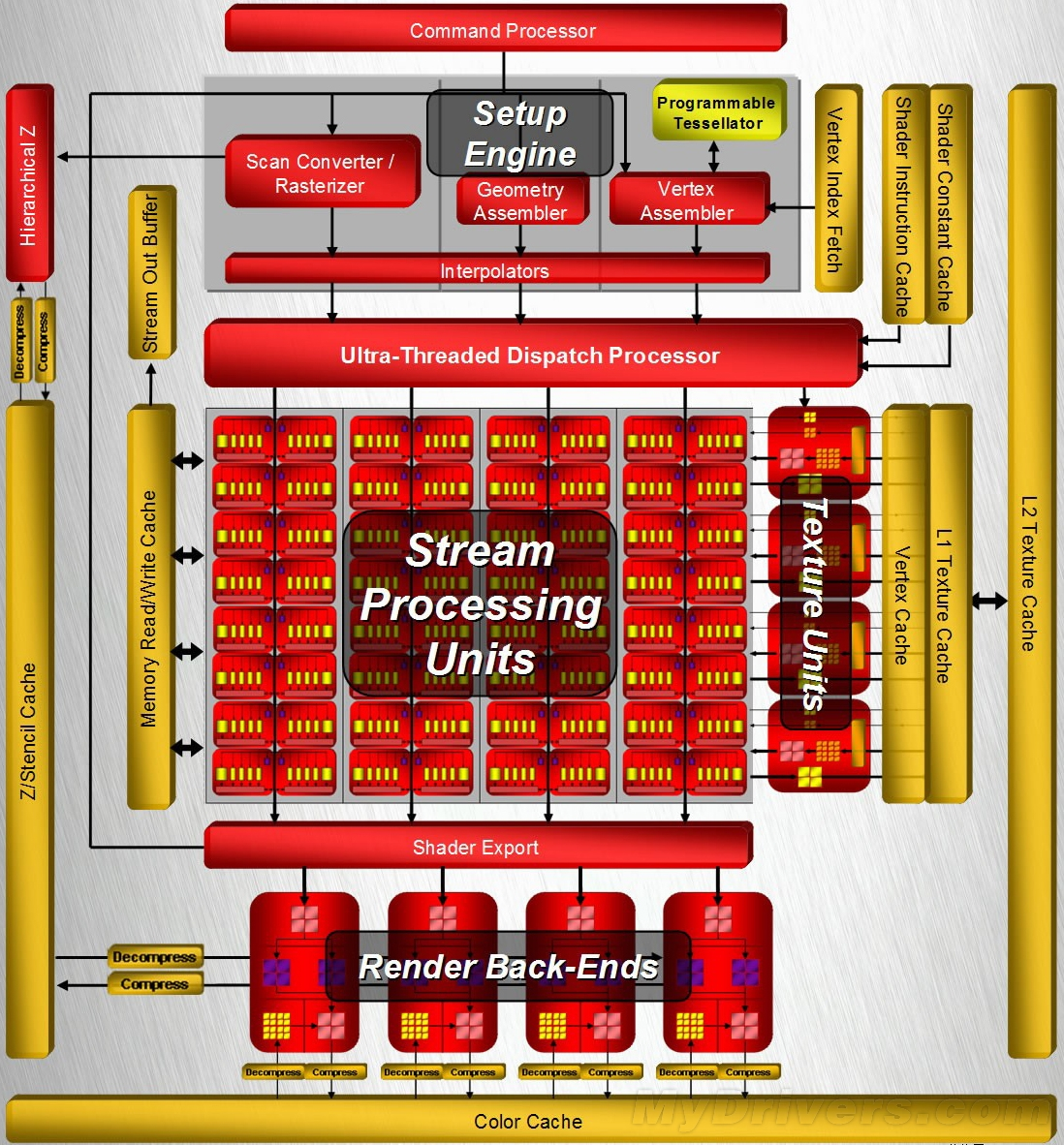
RV670:全球首款55nm工艺
RV670是全球第一款55nm工艺制程的GPU芯片,集成6.6亿个晶体管,因为内存控制器位宽减半而低于R600,核心面积192平方毫米,内置320个流处理器和16个渲染后端,和R600几乎完全相同,可参考上图,R600抗锯齿性能不佳等问题都在RV670身上得到了解决,第一代UVD视频解码引擎,55nm的生产工艺使得核心面积减小并能装下UVD单元,实现了顶级性能显卡也能实现高清视频硬解码的功能。这些流处理单元被每5个分成一组4D+1D模式的5D向量着色器,具有浓厚传统4D向量着色器特征,支持最高8倍的标准MSAA,256bit位宽的内存控制器、符合PCI Express 2.0规范的I/O接口。AMD还特别引入移动平台上的PowerPlay技术进一步降低显卡的整体功耗。
2007年12月,发布Radeon HD 3850和Radeon HD 3870,均使用研发代号为RV670 GPU。
下表为Radeon HD 3850和Radeon HD 3870参数规格:
产品型号 | Radeon HD 3850 | Radeon HD 3870 |
核心代号 | RV670 | RV670 |
工艺制程 | 55nm | 55nm |
晶体管数 | 6.66亿 | 6.66亿 |
核心频率 | 669MHz | 777MHz |
流处理器 | 320 | 320 |
纹理单元 | 16 | 16 |
光栅单元 | 8 | 8 |
显存类型 | GDDR4/GDDR3 | GDDR4/GDDR3 |
显存容量 | 1GB/512MB | 1GB/512MB |
显存位宽 | 256bit | 256bit |
输出接口 | D+DL+DVI(HDMI adaptor) | sVGA+DDVI+VO(HDMI adaptor) |
高清技术 | Avivo HD | Avivo HD |
DirectX | 10.1 | 10.1 |
RV770
2008年,RV770发布,全球第一颗单芯片突破一万亿次单精度浮点运算能力、单芯片突破2000亿次双精度浮点运算能力的电脑芯片。RV770集成9.56亿个晶体管,SIMD阵列扩充为10组,流处理器数量增加为800个,轻松突破1TFLOP的浮点运算能力,每组SIMD还绑定了专属的缓存及纹理单元,纹理单元增加到10组,总计40个,支持最高16倍的标准MSAA,支持DirectX 10.1,第二代UVD视频解码引擎,第二代PowerPlay技术。RV770运算资源的大幅度扩充带来了Shader单元的性能提升,而AMD-ATI研究改进了RBE单元,主要用来实现多重采样和抗锯齿以提高画质或降低高画质下GPU的性能衰减。
Radeon HD 4850,55nm工艺制程,9.56亿个晶体管,核心面积达到260平方毫米,GDDR3显存,256bit的显存位宽,512MB的显存容量,63.6GB/s的显存带宽,核心频率625MHz,800个流处理器,40个纹理单元,16个光栅单元,浮点运算能力达到接近1TFLOPS,支持DirectX 10.1和Shader Model 4.1。
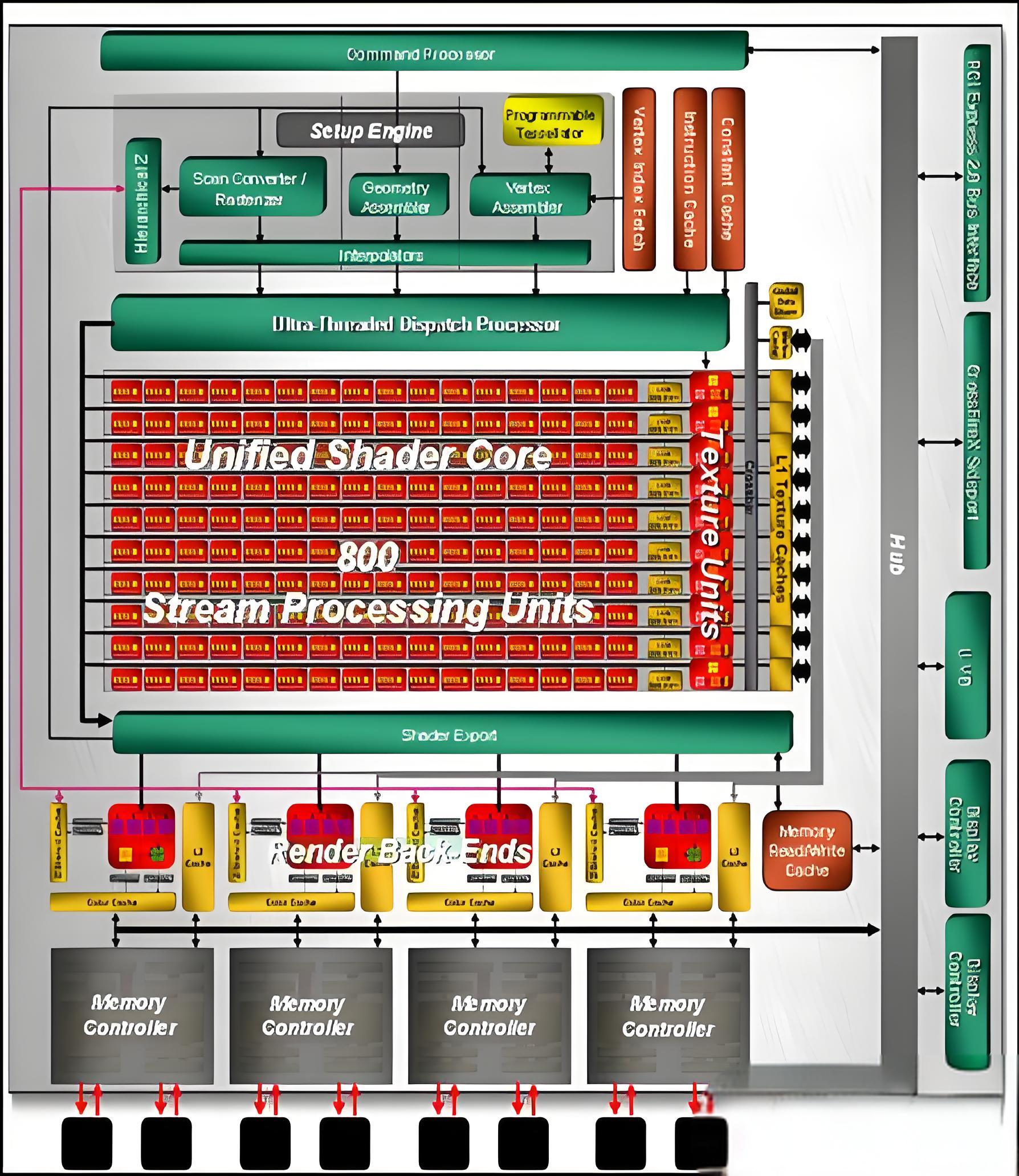
稍后推出的Radeon HD 4870,55nm工艺制程,800个流处理器,40个纹理单元,16个光栅单元,AMD-ATI采取了更为精准的显存策略,引入了256bit的GDDR5显存,回归了传统的显存控制器设计,并且将显存频率提升到了3.6 GHz,性能得到了显著提升,率先支持GDDR5显存,成为业界第一款支持GDDR5显存的GPU产品,512MB的显存容量,115.2GB/s的显存带宽,核心频率750MHz,浮点运算能力达到1.2 TFlops,支持DirectX 10.1。
RV740:第一代40nm工艺
RV740,首款采用40nm工艺制程的核心,配备640个流处理器,32个纹理单元,16个光栅单元,128bit的显存位宽,512MB GDDR5显存,浮点计算能力达到900GFLOPS。RV740可以说是AMD对于40nm工艺的一次试水,为之后的RV870使用40nm工艺铺平了道路。
Radeon HD 4770,RV740核心,40nm工艺制程,集成8.26亿个晶体管,核心面积达到140平方毫米,640个流处理器,32个纹理单元,16个光栅单元,浮点运算达到900GFLOPS,核心频率700MHz,128bit的显存位宽,512MB GDDR5显存,51.2GB/s显存带宽,支持DirectX 10.1、PCI-E 2.0、UVD2。HD 4770本身并不是一款主要产品,但它给AMD带来了无法估量的经验,让AMD体验到了台积电陷入困境的40nm工艺。
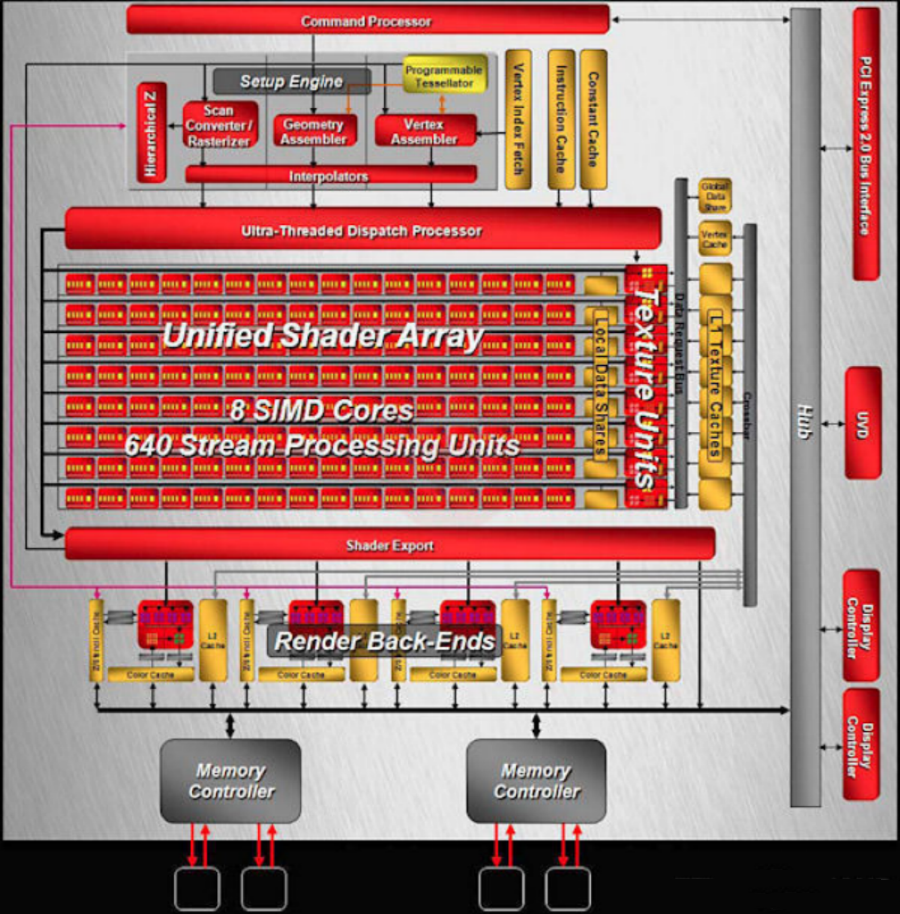
RV870:第二代40nm工艺
2009年,AMD发布基于DirectX 11的Radeon HD 5870,RV870 GPU核心架构,第二代40nm工艺制程,1600个流处理器,32个光栅单元,核心面积334平方毫米,核心频率580MHz,1024MB GDDR5显存,256bit的显存位宽,153.6GB/s的显存带宽,支持PCI Express X16 2.0、DirectX 11、Shader Model 5.0、OpenGL 3.1。最为关键的是Radeon HD 5870满足了DirectX 11的一切设计要求,同时取得了对NVIDIA上一代单卡Geforce GTX285的全面领先。
按照AMD初始计划,在Radeon HD5000系列之后将会转向新的核心架构,制造工艺也会更新,但40nm工艺很长时间才成熟起来并且取消32nm工艺而直奔28nm,AMD随之被迫更改了产品研发和发布计划,于是就有了新的“北方群岛”(Northern Islands),也就是Radeon HD 6000系列。
Radeon HD 6000系列:引入第三代 UVD
照AMD的说法,Radeon HD 6000系列架构重点有五大方面的进步:
1、更强的单位面积性能,比上代提升最多35%;
2、第二代DX11设计,更快的曲面细分和几何吞吐;
3、新的和改进的画质功能,包括抗锯齿和各向异性过滤;
4、增强的多媒体加速,包括UVD3硬件解码引擎、AMD APP并行异构计算技术、蓝光3D立体技术;
5、下一代显示技术,包括Eyefinity+多屏输出、HDMI 1.4a规范、DisplayPort 1.2规范。
Radeon HD 6870:核心代号Bart,集成17亿个晶体管,1120个流处理器,56个纹理单元,32个ROP单元,支持第三代UVD视频解码引擎、DirectX 11。整体依然沿用了自R600(HD2900XT)以来的SIMD(单指令多数据流)架构,流处理器部分没有太多改进,历代产品的改进都是集中在周边控制模块上面。SIMD整列降到14组,流处理器降到1120个,核心频率900MHz,1G GDDR5显存,256bit的显存位宽,133.4GB/s的显存带宽。
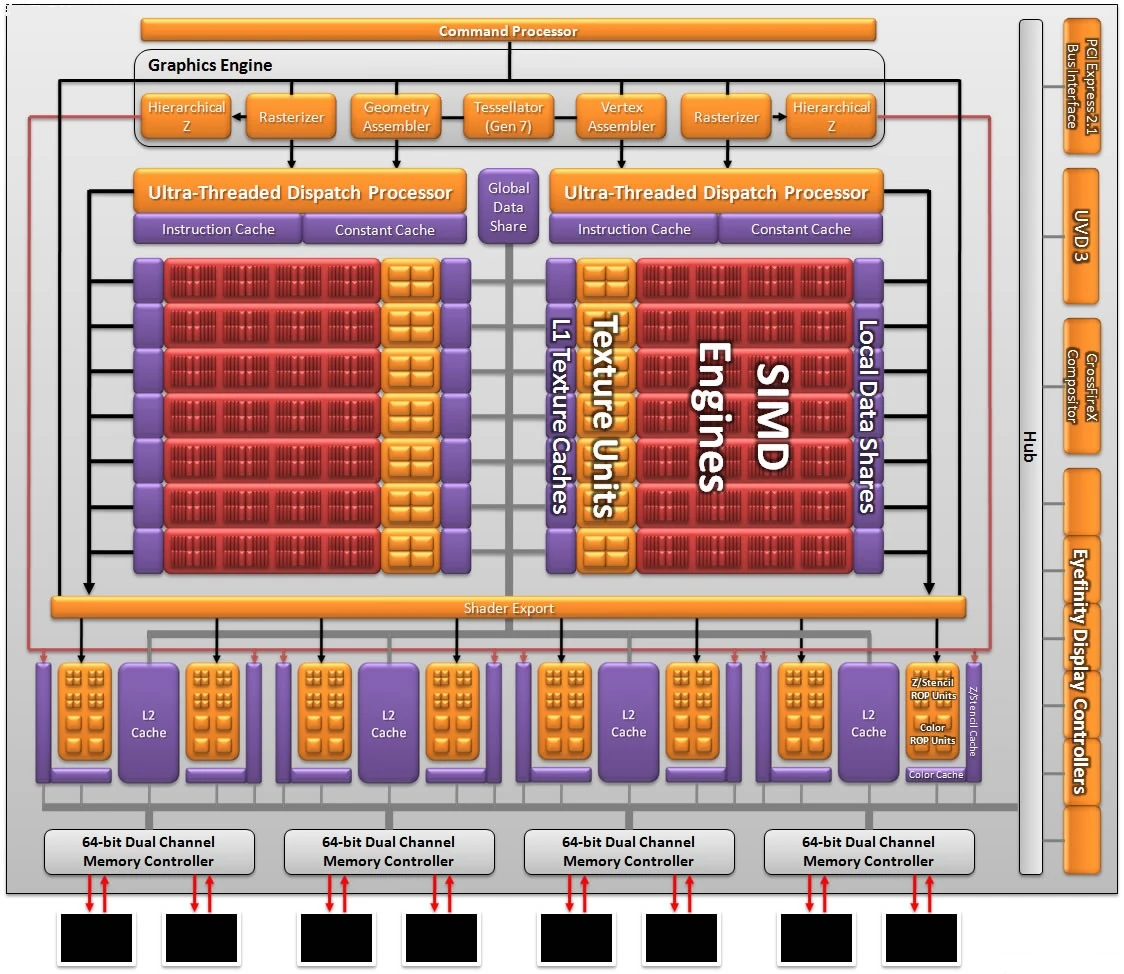
Radeon HD 6970:核心代号Cayman,40nm工艺制程,26.7亿个晶体管,核心面积389平方毫米,1536个流处理器,96个纹理单元,32个ROP单元,核心频率880MHz,2 GB GDDR5显存,176GB/s的显存带宽,256bit的显存位宽,TeraScale 3统一处理架构,支持DirectX 11,第三代UVD视频解码引擎。
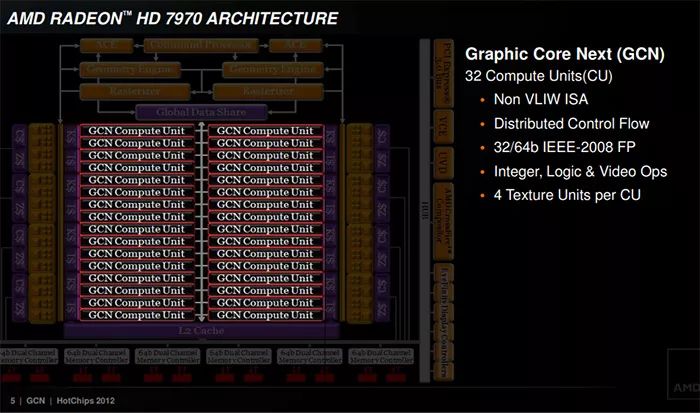
GCN:Tahiti
2012年,AMD发布Radeon HD7000系列,推出新升级的GCN架构且之后一直延续了四代,在构架上实现创新,第一款采用28nm工艺制程的GPU图形芯片,代号Tahiti,架构GCN(Graphic Core Next),至此,GCN架构首次面世。
GCN集成43亿个晶体管,采用硬件与软件协同工作的方式,提供出色的图形处理与计算能力。GCN架构不仅拓宽DirectX 11游戏的范围,而且也是AMD专为一般运算打造的第一款设计。完整的GCN核心含有32个CU(计算单元),每个CU内部包含4组SIMD阵列,2048个流处理器,每个单元中包含一个标量协处理器,能够处理传统处理器排斥的工作负载和编程语言。架构还是基于SIMD体系,4组SIMD阵列同步运行使得每个CU单元每周期可以执行4线程。6组GDDR5显存控制器,每组64bit,显存位宽为384bit,显存带宽达到264GB/s,显存容量达到3GB。
GCN架构在AMD Radeon HD7000系列显卡中首次引入,第一款产品名为HD7970,流处理器由4-Ways VLIW SIMD架构(称4D架构)改良,HD7970集成43.1亿个晶体管,包含32个CU,128组SIMD阵列,2048个流处理器。
GCN2:Hawaii
2013年,在GCN构架基础上加以优化,推出第二代GCN架构,核心代号Hawaii,提供更多的计算单元、更高的频率和更大的缓存容量,首次出现在Radeon R9系列产品中。GCN2由GCN架构持续进化,首先大幅度增加了CU单元的数量,从HD7970的32个CU单元提升到44个(由4组Shader Engine渲染引擎组成,每组又包含11个CU单元),流处理器数量提升到2816个,纹理单元达到176个。
R9 290X,第二代GCN架构Hawaii核心,采用28nm工艺制程,核心频率1000MHz,核心面积438平方毫米,512bit的显存位宽,320GB/s的显存带宽,支持DirectX 11.2,支持GDDR5,功耗最大可达250W,2816个流处理器,176个纹理单元,64个ROP单元。

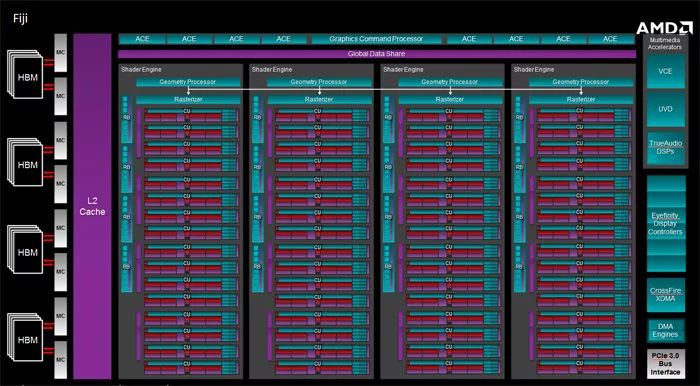
GCN3:Fiji
2013年,推出GCN3架构,核心代号Fiji,集成89亿个晶体管,这一代中AMD进一步增加了计算单元的数量,达到了64个,4096个流处理器,256个纹理单元,64个ROP单元,核心面积达到596个平方毫米,首次出现在AMD Radeon R9 300系列产品中。
Fiji核心前端单元与之前没有变化,8组ACE单元,4组几何单元,4组渲染引擎,但CU计算单元数量增加到了64组,每组渲染引擎单元包含了16组CU单元,之前的Hawaii是每组11个CU单元。另一个值得注意的变化是显存控制器,Hawaii是8组64bit GDDR5主控,总计512bit位宽,而Fiji核心增加了HBM显存支持,所以有4组HBM显存控制器。
R9 Fury X,GCN3架构,核心代号Fiji,采用28nm工艺制程,集成89亿个晶体管,核心频率1050MHz,4096个流处理器,256个纹理单元,64个ROP单元,支持HBM显存,显存容量4096MB,4096bit的显存位宽,512GB/s的显存带宽,支持DirectX 12/Mantle/OpenGL 4.5。
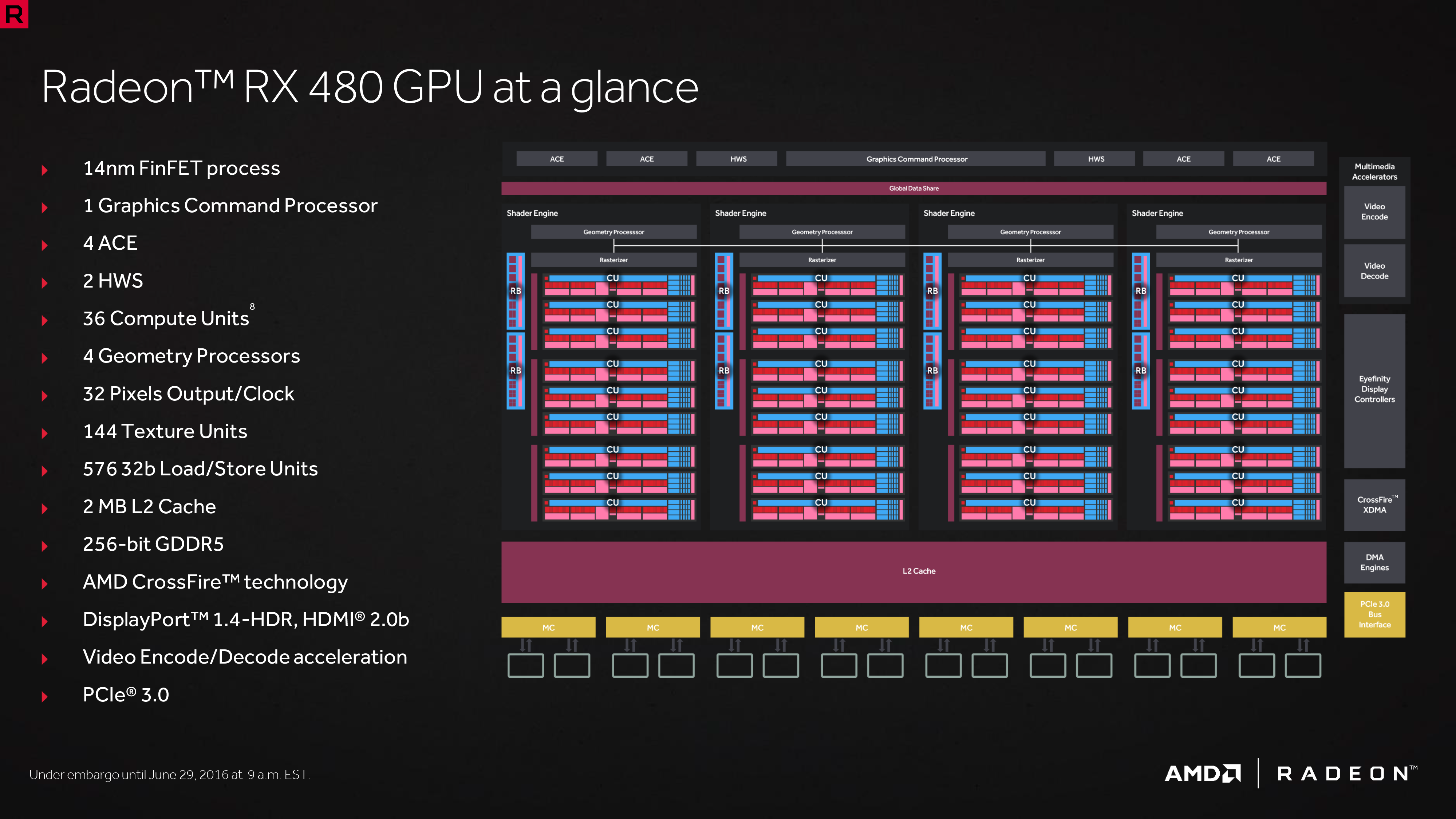
GCN4:Polaris
2016推出,采用更先进的14nm工艺制程,提供更低的功耗及更高的频率,首次出现在AMD Radeon RX 400系列产品中。
Radeon RX 480采用14nm FinFET工艺,核心面积为232平方毫米,每瓦性能提高1.7倍,之后优化后提高到2.8倍,包含36个CU单元,2304个流处理器,144个纹理单元,4个带宽为64bit的双通道显存控制器组成了总量为256bit的显存控制单元,256GB/s的显存带宽,功耗150W,完整支持DirectX 12API以及异步运算,拥有5.8TFLOPS的高单精度浮点运算能力,照比上代提升了65.7%。通过HDMI接口2.0b接口可以实现最高3840x2160分辨率60Hz的显示输出。
图中,RX480配备4颗原生异步引擎(ACE),在VR应用中将发挥出更强大的性能。
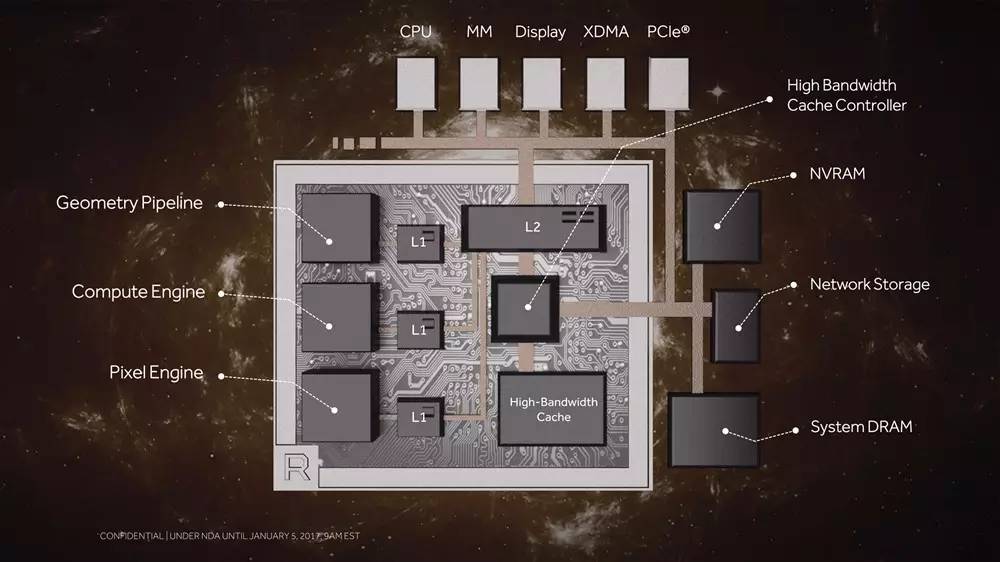
GCN5:Vega
2017年推出Vega,全新内存层次结构,与传统GPU相比,其为PC游戏、专业设计和机器智能开启全新可能。Vega采用高带宽缓存控制器(HBCC),通过细粒度数据移动方式,可以灵活地,可编程地访问封包上缓存和封包外内存,以及下一代计算单元设计,支持高级图形与高性能计算任务;首次出现在AMD Radeon RX Vega系列产品中。
Vega共64组CU单元4096个流处理器单元,Vega的微构架被称为“NCU(下一代计算单元)”每个NCU中有64个ALU,大幅度提升了深度学习计算性能,除了内核的改进,Vega重点还是围绕HBM2显存来的,频率提升到1890MHz,实现了484GB/s的带宽。
Vega的进步亮点包括:
先进的GPU内存架构:全新高带宽及控制器,该缓存采用先进的HBM2技术,每秒能够传输TB级数据,与上一代HBM技术相比,每个引脚带宽增加了一倍。 HBM2还可以在GDDR5内存占用量不到一半的情况下,实现更大容量。Radeon VEGA架构针对流式处理海量数据集进行了优化,可以与多种类型内存一起工作,最多可提供512TB虚拟地址空间。
下一代几何管线:使用了令人难以置信的复杂几何,令数据采集设备分辨率迅猛增加。下一代几何管线使程序员在处理这种复杂几何图形方面获得令人难以置信的效率,同时与前几代Radeon架构相比,每时钟周期吞吐量提升超过200%。
下一代计算引擎:VEGA架构核心是一个基于灵活计算单元的下一代计算引擎,它可以在本地每个时钟周期2内处理8位,16位,32位或64位操作,并且AMD优化了计算单元,该架构在工作负载上具有高度通用性。
高级像素引擎:VEGA像素引擎采用绘制流分档光栅器,旨在提高性能和功耗效率,可以使用板载二级缓存,显著降低那些频繁执行写后读操作的图形工作负载的系统开销。
自2017年GCN第五代(也为最后一代)后,GCN便将其微架构划分游戏向的RDNA和计算向的CDNA;
RDNA
2019年,AMD推出RDNA架构,核心代号Navi,台积电7nm工艺制程,GDDR6显存,支持PCI Express 4.0接口,支持Wave32和Wave64两指令长度模式。同时兼容GCN架构,在性能、功耗、能效等方面实现飞跃,开启第五代架构革新,相比GCN架构在能耗比上提升了50%。AMD称其为专为游戏而生的DNA。RDNA架构拥有2组SIMD32单元(支持Wave32长度指令,一个Wave64指令可以同时由两个SIMD32单元运行),2个共享向量单元和2个共享标量单元。
完整的RDNA GPU含40个CU单元,2560个流处理器,80个标量单元,160个64位双线性过滤单元。
Radeon RX 5700构架方面主要是3大部分:
Radeon Display Engine,包含对新一代高分辨率HDR显示技术的支持和新一代压缩等级;
Radeon Multi-Media Engine,包括无缝串流和改进后的编码;
RDNA图形架构,包括新的计算单元、多级缓存、高效图像引擎;(主角)
完整的Radeon RX 5700 XT核心包括40个RDNA计算单元,意味着包含80个Scalar Processors、2560个流处理单元和160个64b的双线过滤单元。缓存部分包含4MB L2和512KB L1缓存。图形引擎部分具备64个像素单元、4个异步计算引擎,同时整个架构也为低压高频工作而设计。


RDNA2
2020年,AMD发布新一代RX 6000系列显卡,推出第二代RDNA架构,采用第一代光线追踪加速器,全新视觉渲染管线和第一代AMD Infinity Cache技术,台积电7nm工艺制程,集成286亿个晶体管,集成286亿个晶体管,128MB的超大缓存容量,带来了前所未有的带宽提升和延迟降低,峰值达到2TB/s。
RDNA2基本构架维持了RDNA的设计,保留了之前双CU设计,一个双CU单元包含2个CU,每组CU分别可以执行2个SIMD 32指令,CU数达到80个,拥有L0、L1、L2以及无线缓存,显存控制单元5个层级,Shader Engine增加到4个,SP个数达到5120个。Shader Engine内部变化,不再有两个完全独立的Shader Array,CU数量合并,其他资源共享。RDNA2开始支持Ray tracing,每个CU内部集成一个RA(Ray Accelerater),每个RA提供4x Ray/Box求交测试,1x Ray/Triangle求交测试。
RDNA2架构的主要三个亮点:
高频设计:基于架构优化,每个CU频率是上代的1.3倍,而功耗在相同频率下比上代降低了50%。
Infinity Cache设计:第一代AMD Infinity Cache技术,最大容量128MB。
DirectX 12 Ultimate:支持DirectX 12 UItimate功能,包括DXR光线追踪、VRS可变速率着色、MESH网格着色器、Sampler Feedback采样器反馈。
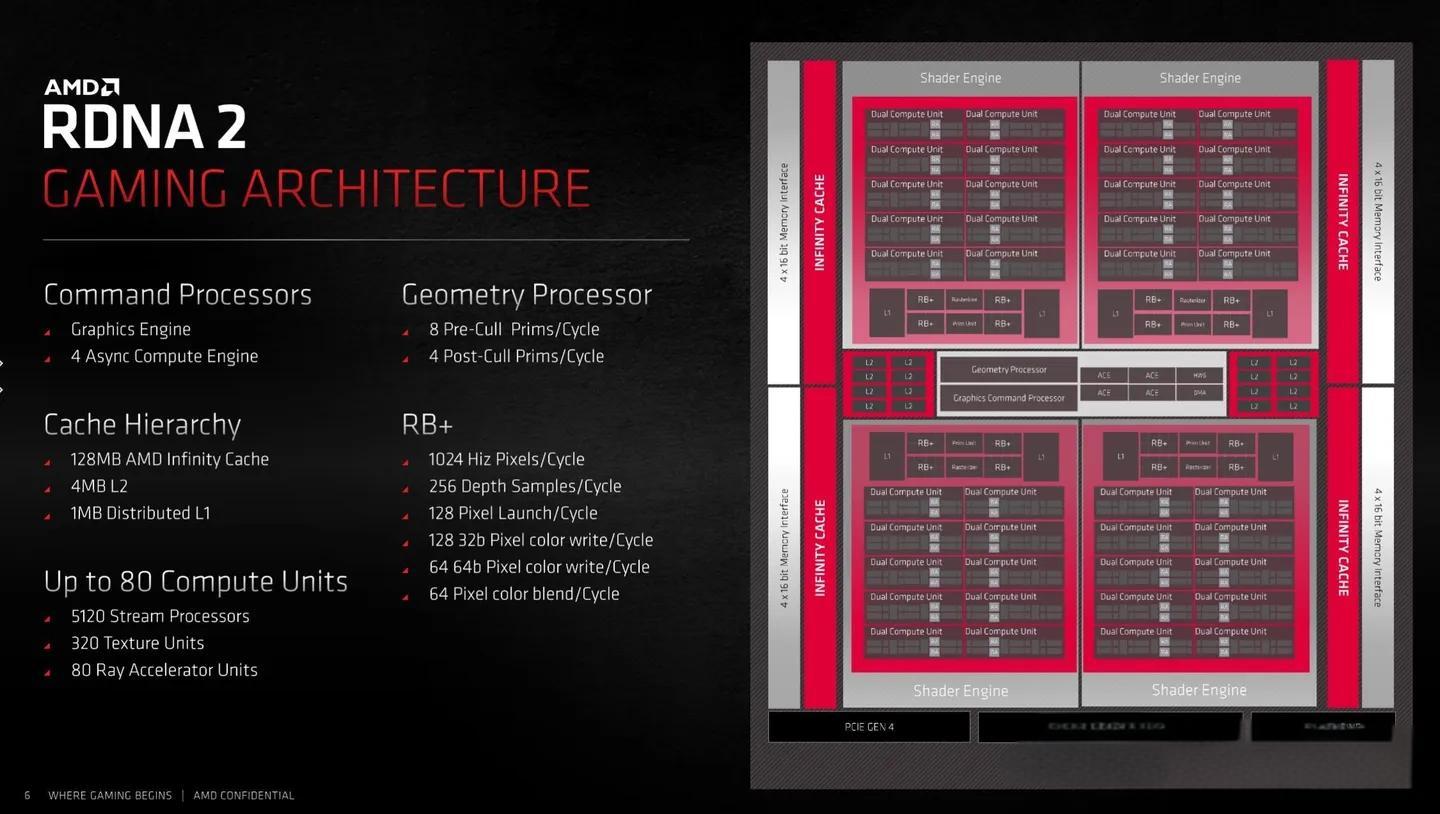
RX 6900XT,采用7nm工艺制程,Navi 21核心,配备80个CU、5120个流处理器、320个纹理单元,RA加速单元采用的是每个CU配备1个的设计,RA单元也提升至80个。游戏核心频率2015MHz,加速频率2250MHz,16GB的GDDR6显存,128MBIF的高速缓存,256bit的显存位宽,512GB/s的显存带宽,功耗最大达到300W。
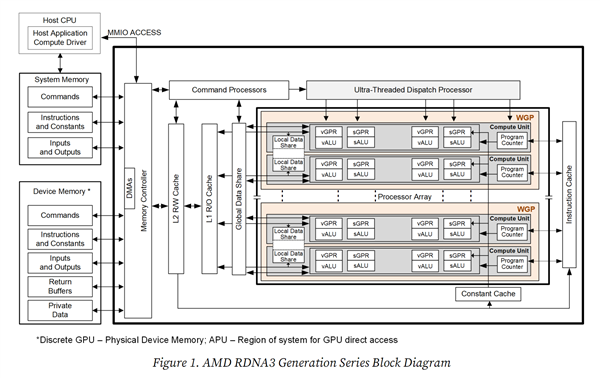
RDNA3
2022年,AMD正式发布全新的采用“RDNA3”架构的Radeon RX 7900系列显卡。
采用超快的第二代 AMD Infinity Cache 技术,通过超高带宽小芯片互连技术进行连接,集成580亿个晶体管,峰值带宽可达5.3 TB/s;最重要的Navi31核心拥有1个全新5nm制程工艺、拥有多达96个计算单元、尺寸为300平方毫米的图形计算芯片(GCD)与6个6nm制程工艺的、尺寸为37.5平方毫米 的全新多缓存I/O芯片(MCD),每颗MCD都具备容量高达16MB的第二代AMD高速缓存。Navi31也直接采用了源自CPU上的Infinity Fabric互联技术,与前代的Navi21相比,Navi31核心的L1缓存从128KB per Array翻倍到了256KB per Array,同时L2缓存从4MB增加到了6MB。全新统一的 AMD RDNA 3计算单元采用全新人工智能加速器和第二代光线追踪加速器,最高可达2.7倍的AI加速性能提升,最高可达50%的每计算单元光线追踪性能提升,多媒体编码效率也得到提升,支持8K 60Hz的AV1编码和解码。
RX 7900XT,Navi31核心,台积电5nm/6nm工艺制程,配备84个CU单元,5376个流处理器,20GB的GDDR6显存,190bit的显存位宽,功耗750W。
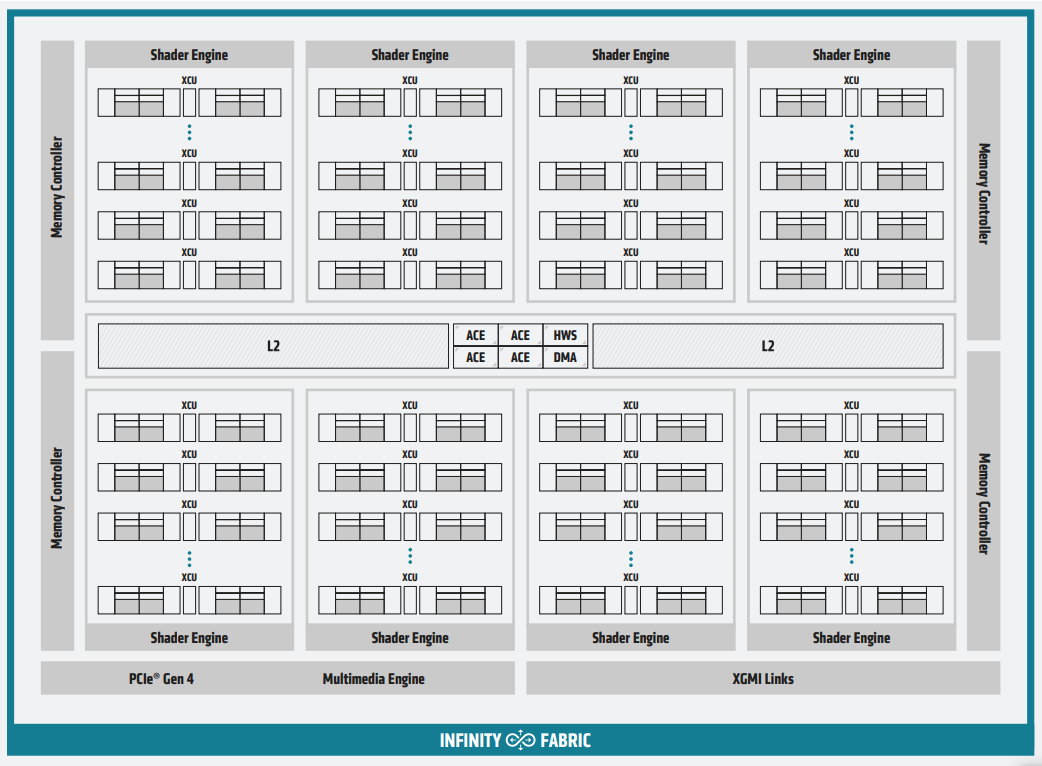
CDNA
2020年,随着Instinct MI100计算卡的发布,正式采用针对HPC高性能的计算、人工智能全新设计的CDNA架构,CDNA架构分为4个ACE(异步计算单元),每个ACE包含了40个CU(计算单元),共120个CU,7680个流处理器。
Instinct MI100计算卡采用台积电7nm工艺制程,配备120个CU,7680个流处理器,核心频率最高1502MHz,并专门加入了核心矩阵Matrix Core,用于加速HPC、AI计算,整合封装了32GB HBM2显存,4096bit的显存位宽,1228.8GB/s的显存带宽,高达11.5TFLOPs峰值FP64性能。
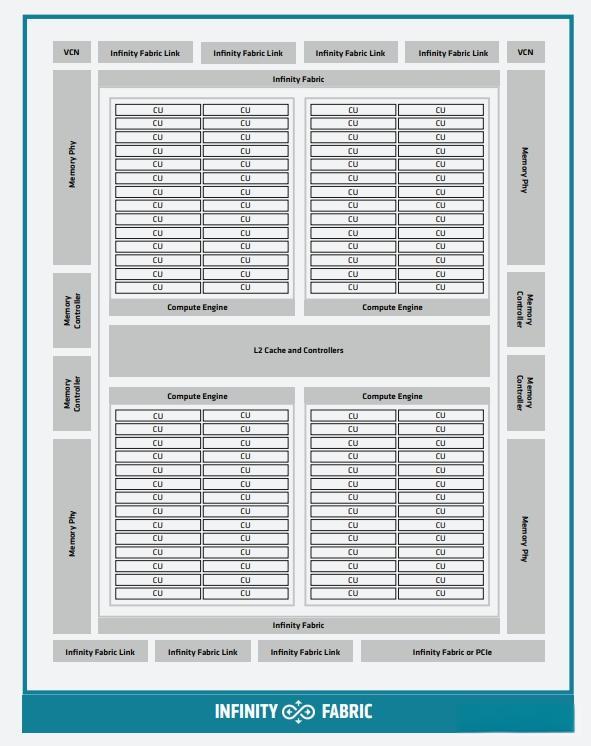
CDNA2
2021年,AMD Instinct MI200系列加速器凭CDNA 2架构,在HPC性能方面可提供极具突破性的提升。和CDNA1比,CDNA2架构的一个重要创新是使用了AMD独特的Infinity Fabric来扩展跨封装的on-die模组,这样每个GCD都可以作为共享内存系统中的一个GPU使用。在计算单元方面,CDNA2架构划分为4个计算引擎CE,每个CE包含28个CU,总共包含了112个物理CU。CDNA2内核可加速FP64和FP32矩阵运算,FP64理论峰值可达上一代的4倍。CDNA2的设计与RDNA3有一点相通,都会采用MCM多芯分装方式,内部同时集成两个die,核心规模翻倍。
Instinct MI200系列计算卡,全新CDNA2架构,台积电6nm工艺制程,集成580亿个晶体管,第三代AMD Infinity Fabric技术,超过14000个内核以及高达128GB的HBM2e显存,FP32性能达到95TFLOPs。业界首个采用2.5D Elevated Fanout Bridge技术(EFB)的多芯片GPU设计,与AMD前代GPU相比,可提供1.8倍的核心数和2.7倍的显存带宽,以及业界领先的每秒3.2 terabytes的理论峰值显存带宽。
Instinct MI250X计算卡含14080个流处理器,220个计算单元,8192bit的显存位宽,3276.8GB/s的显存带宽,最大功耗可达500W,可为双精度(FP64)高性能应用程序提供更强的性能,并为AI工作负载带来超过380 TFLOPS的理论半精度(FP16)峰值,通过强大的性能进一步加速由数据驱动的研究。
CDNA3
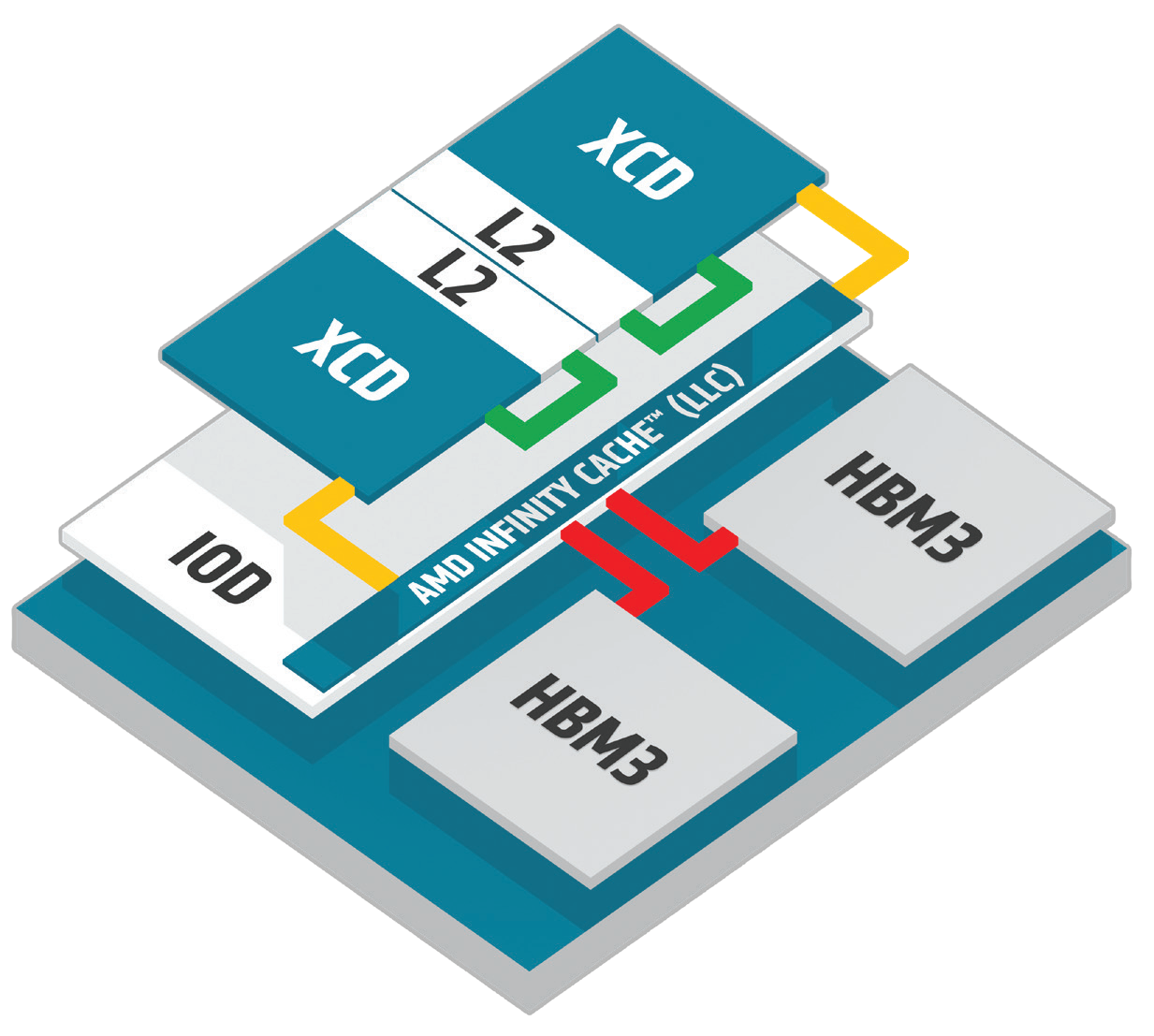
2023年,Instinct MI300系列基于最新第三代CDNA架构推出。在GPU布局上,CDNA 3使用芯片组合技术,有8个计算芯片XCD以及4个IO芯片构成完整产品,为解决内存带宽的瓶颈,CDNA 3从RDNA消费者GPU中引入了“无限缓存”技术,大大提高了缓存带宽。CDNA 3在延续CDNA 2的基础上进行了改进,增加了矩阵运算吞吐量,同时改进了调度机制,提高了FP32的利用率。指令缓存容量也有所增加,帮助容纳更大更复杂的计算内核。
Instinct MI300X,集成1530亿晶体管,192GB的HBM3显存,5.3TB/s的峰值显存带宽,896GB/s Infinity Fabric互连带宽,支持大模型训练和推理。采用8个计算芯片XCD(包含304个CDNA3计算单元)、4个IO芯片,8个HBM3堆栈,高达256MB的AMD Infinity Cache和3.5D封装的设计,支持FP8和稀疏性等新数学格式,全部面向AI和HPC工作负载。Instinct MI300X支持客户将8个GPU整合为一个性能主导型节点,并且具有全互联式点对点环形设计。在模型训练上,AMD MI300X在和英伟达H100相比时也不逊色。MI300X实现了计算核数、带宽及内容容量的显著增加,支持稀疏性和TF32、FP8等新数据格式,提供的性能达到上一代的3.4倍。

本期内容和大家一起回顾了AMD GPU的演进之路,我们见证了GPU技术的飞速发展,从最初的R600到现在的CDNA3,每一次的迭代都为我们展现了前所未有的性能提升与体验升级,更是一场精彩绝伦的视觉盛宴。早期的AMD GPU架构,虽然面临着诸多技术难题和市场挑战,但团队凭借着对技术的深厚理解和创新精神,不断攻克难关,逐步奠定了自己的市场地位。展望未来,让我们共同期待AMD在GPU领域的更多精彩表现,共同见证科技的力量。
参考资料:
[1]https://blog.csdn.net/u013829933/article/details/101370410
<