 2024-04-11
2024-04-11 阅读:954
阅读:954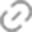 来源:曲速超为
来源:曲速超为超越英伟达H100!英特尔Gaudi3发布:训练快40%,推理快50%!
文章转载自芯智讯 网址:https://mp.weixin.qq.com/s/kz0vl-2lf4lvAHfEEqV7_Q

北京时间4月9日晚间,英特尔在美国召开了“Intel Vision 2024”大会,介绍了英特尔在AI领域取得的成功,并发布了新一代的云端AI芯片Gaudi 3及第六代至强(Xeon)可扩展处理器,进一步拓展了英特尔的AI产品路线图。
AI芯片市场的巨大机遇
在生成式AI持续爆发背景之下,市场对于AI芯片的需求正高速增长。根据市场研究机构Gartner最新预测,到2024年AI芯片市场规模将较上一年增长 25.6%,达到671亿美元,预计到2027年,AI芯片市场规模预计将是2023年规模的两倍以上,达到1194亿美元。
英特尔也表示,到2030年,半导体市场规模将达1万亿美元,人工智能是主要推动力。创新技术正在以前所未有的速度发展,每家公司都在加速成为AI公司,这一切都需要半导体技术提供支持。从PC到数据中心再到边缘,英特尔正在让AI走进千行百业。

在边缘AI市场,英特尔已经发布了涵盖英特尔酷睿Ultra、英特尔酷睿、英特尔凌动处理器和英特尔锐炫显卡系列产品在内的全新边缘芯片,主要面向零售、工业制造和医疗等关键领域。英特尔边缘AI产品组合内的所有新品将于本季度上市,并将在今年年内获得英特尔刚刚发布的Intel Tiber边缘解决方案平台的支持,以简化企业软件和服务的部署,包括生成式AI。
对于去年推出的面向AI PC产品的英特尔酷睿Ultra处理器,凭借强大的AI内核,为生产力、安全性和内容创作提供了全新能力,并为企业焕新其PC设备提供了巨大动力。英特尔预计将于2024年出货4000万台AI PC,以及超过230种的设计,覆盖轻薄PC和游戏掌机设备。同时,英特尔透露将于2024年推出的下一代英特尔酷睿Ultra客户端处理器家族(代号Lunar Lake),将具备超过100 TOPS平台算力,以及在神经网络处理单元(NPU)上带来超过46 TOPS的算力,从而为下一代AI PC提供强大支持。
在面向云端的数据中心市场,英特尔在2022年就推出了AI加速芯片Gaudi 2,在去年年底还推出了集成了AI内核的代号为“Emerald Rapids”的面向数据中心的第五代 Xeon处理器。
英特尔公司首席执行官帕特·基辛格表示:“创新技术正在以前所未有的速度发展,每家公司都在加速成为AI公司,这一切都需要半导体技术提供支持。从PC到数据中心再到边缘,英特尔正在让AI走进千行百业。英特尔最新的Gaudi、至强和酷睿平台将提供灵活的、可定制化的解决方案,满足客户和合作伙伴不断变化的需求,把握住未来的巨大机遇。”
Gaudi 3:BF16性能提升4倍,支持1800亿参数大模型
而在云端AI加速芯片市场,英特尔早在2019年12月就斥资20亿美元收购Habana Labs(其于2019 年 7 月推出了 Gaudi 1 加速器),虽然当时英伟达在AI芯片市场的体量还很小,但是在AI芯片的技术积累上,英伟达更为深厚。因此,我们可以看到,当2022年Gaudi 2 推出之时,其也只能与英伟达A100进行对标。
为了进一步加强在云端AI加速芯片市场的竞争力,在此次“Intel Vision 2024”大会上,英特尔正式推出了全新的Gaudi 3。虽然整体得到了大幅提升,但是依然只能是与英伟达上一代的H100/H200竞争。
据介绍,Gaudi 3采用的是台积电5nm工艺,在芯片设计上,Gaudi 3转向了具有两个计算集群的Chiplet的设计,而不是Gaudi 2所采用的单个集群的方案。Gaudi 3 拥有 8 个矩阵数学引擎、64 个张量内核、96MB SRAM(每个Tile 48MB,可提供12.8 TB/s的总带宽) 和 128 GB HBM2e 内存,16 个 PCIe 5.0 通道和 24 个 200GbE 链路 。在计算核心的周围,则是八个HBM2e内存堆栈,总容量为128 GB,带宽为3.7 TBps。


与上一代的Gaudi 2 相比,Gaudi 3在BF16工作负载方面的性能将是Gaudi 2的四倍,FP8性能也将是Gaudi 2 的两倍,网络性能也是Gaudi 2的两倍(Gaudi 2是24个内置的100 GbE RoCE Nic),HBM容量是Gaudi 2的1.5倍。

另外,Gaudi 3 设备中的张量内核支持与 Gaudi 32 相同的 FP32、TF32、BF16、FP16 和 FP8 数据格式,并且不支持 FP4 精度。相比之下英伟达新的Blackwell GPU 将支持 FP2 精度,而英伟达现有的 Hopper GPU 则不支持。英特尔表示,Gaudi 3预计可大幅缩短70亿和130亿参数Llama2模型,以及1750亿参数GPT-3模型的训练时间。此外,在Llama 7B、70B和Falcon 180B大型语言模型(LLM)的推理吞吐量和能效方面也展现了出色性能。
尽管Gaudi 3 与英伟达的Blackwell GPU有着很多相似之处,但英特尔旗下Habana首席运营官Eitan Medina强调,这不是GPU。“GPU传统上是被设计为进行图形渲染,是关于渲染像素的,所以自然而然地,选择实现许多小的执行单元,因为像素就是像素”,他解释道。“图形渲染不需要巨大的矩阵乘法。而Gaudi3 是使用数量较少的非常大的矩阵数学引擎构建的,这些引擎能够更有效地处理 AI 工作负载。”
虽然Gaudi 3是英特尔最新一代的AI加速芯片,相比上一代的Gaudi 2带来了很大的提升,但是其仍然难以与英伟达最新的B200或者AMD最新的MI300X系列竞争。显然,英特尔Gaudi 3 的主要对标的也是英伟达H100/H200。
训练性能比英伟达H100快了40%,推理快了50%
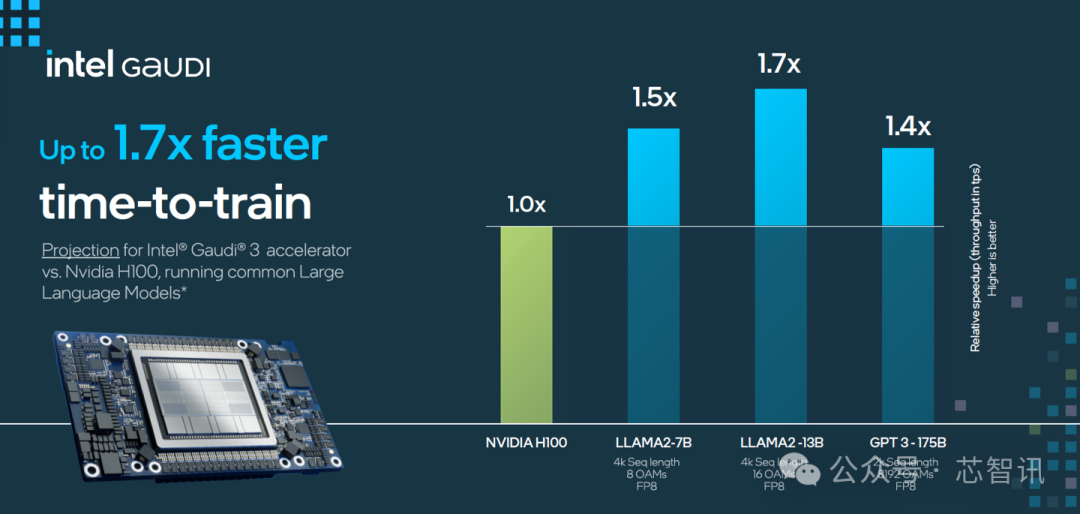
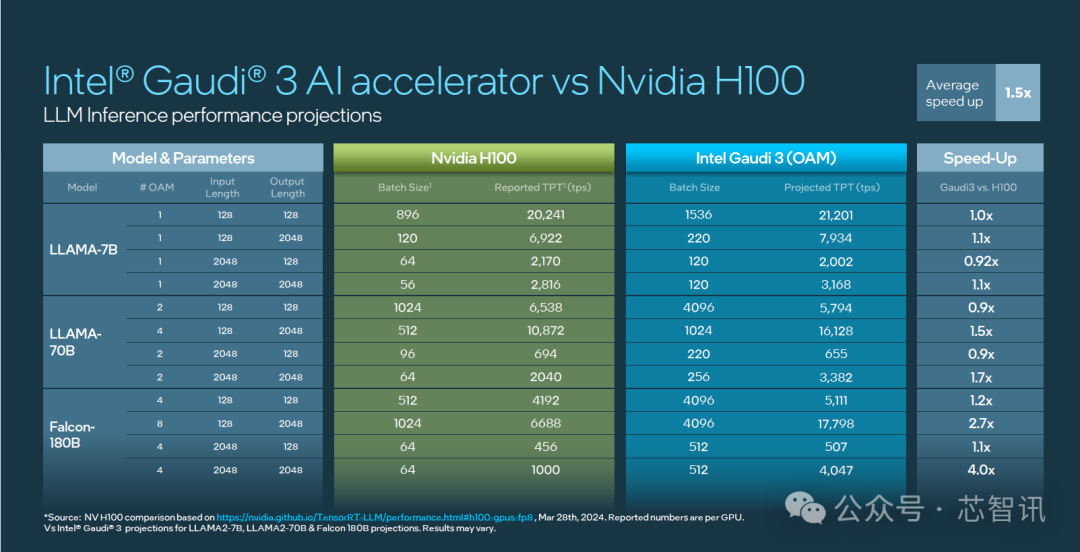
根据英特尔官方公布的数据显示,Gaudi 3 在流行的大语言模型(LLM)训练速度方面,比英伟达H100平均快了40%;在流行大模型的推理能效表现上,比如英伟达H100领先50%。

具体来看,英特尔 Gaudi 3 与英伟达 H100 在相同节点数量下,相关大模型训练时间对比上最高快了1.7倍,其中,LLAMA2 70 亿参数对比有 1.5 倍于 H100 的优势,LLAMA2 130 亿参数最高有 1.7 倍的优势,GPT 3 1750 亿参数有 1.4 倍优势。
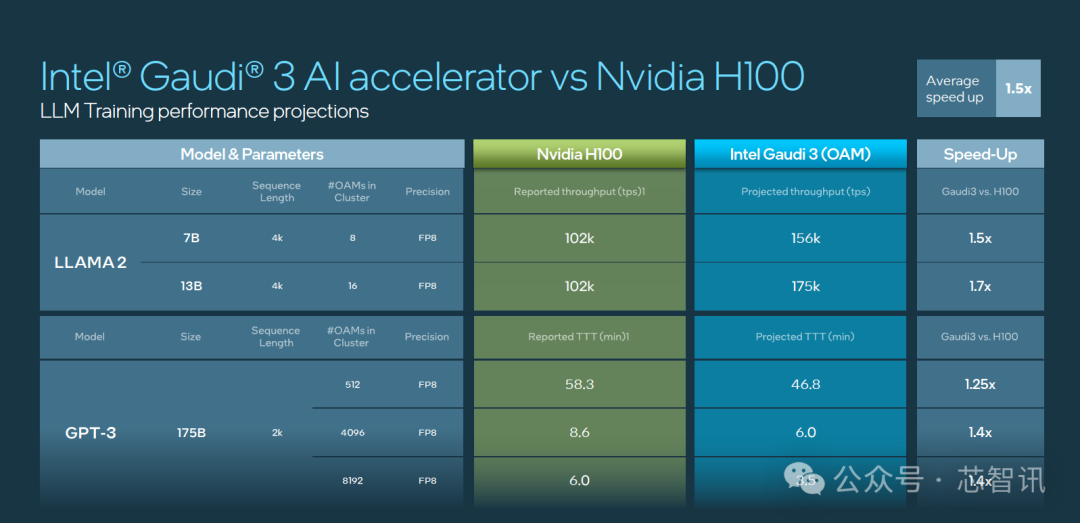
在大模型推理速度表现上,Gaudi 3 相比 H100 平均快了1.5倍,最高快了4倍。
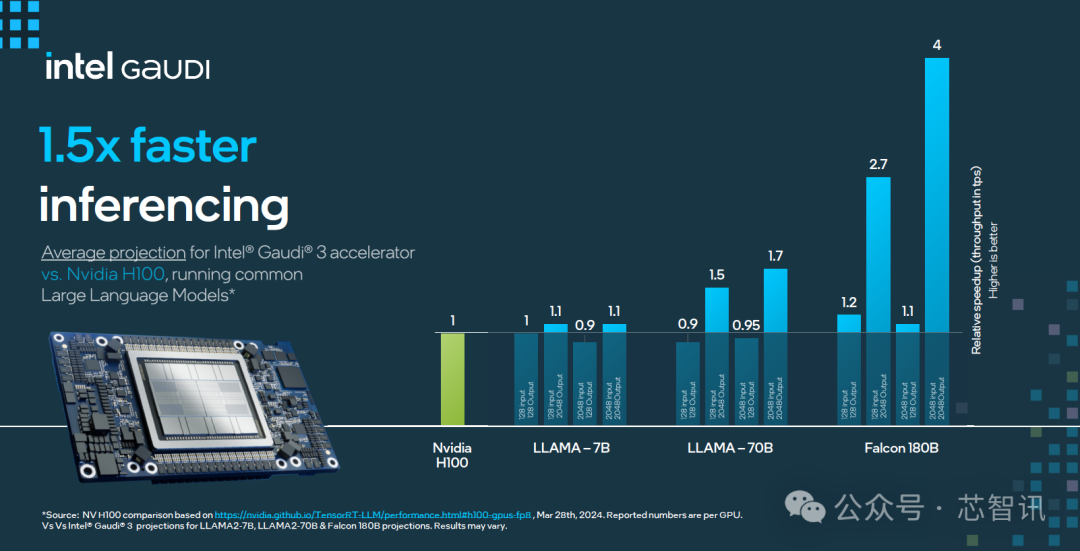
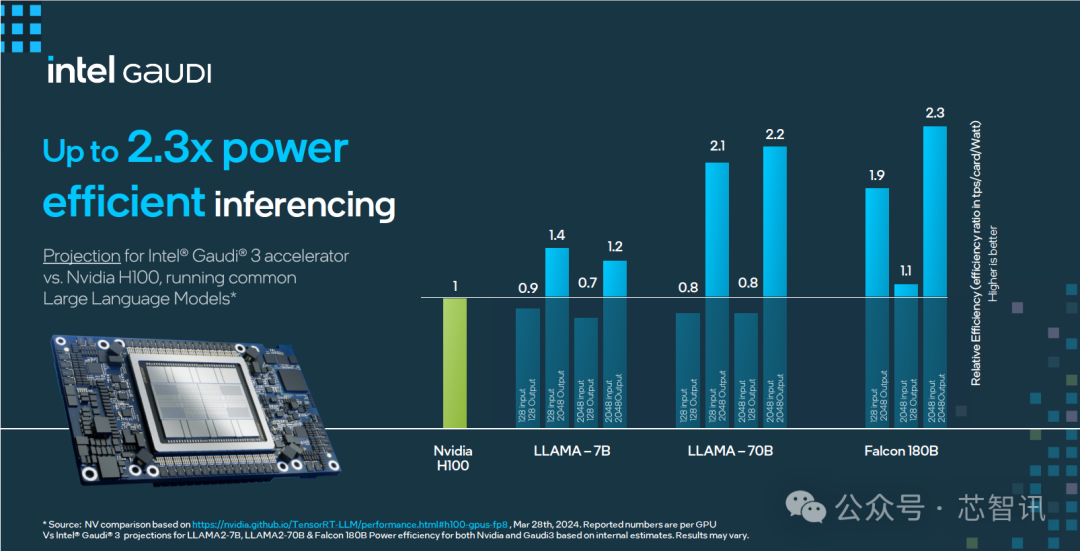
在大模型推理能效表现上,Gaudi 3 相比 H100 最高提升2.3倍。
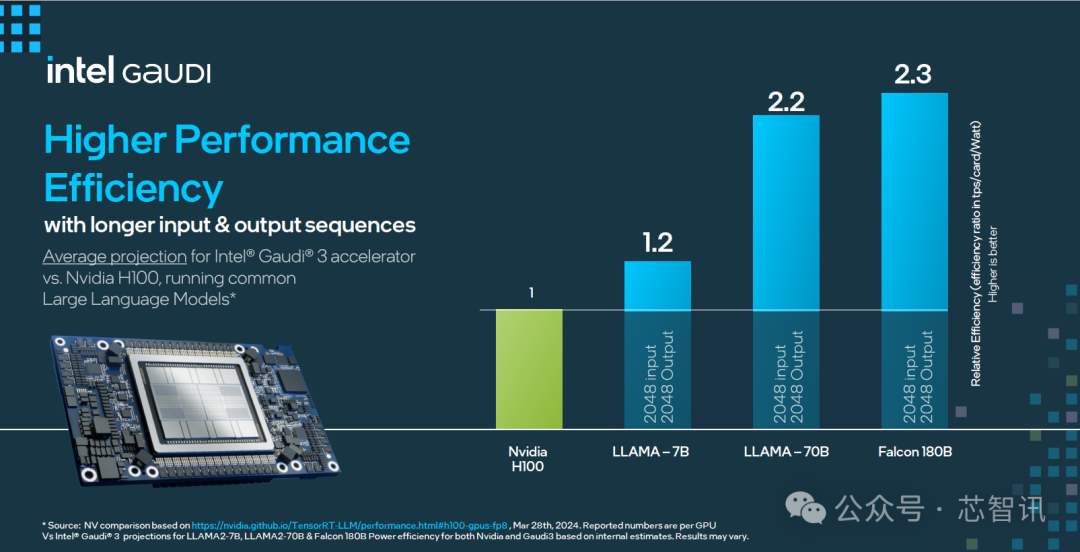
在更高性能的能效表现上,Gaudi 3 相比 H100 最高也提升了2.3倍。
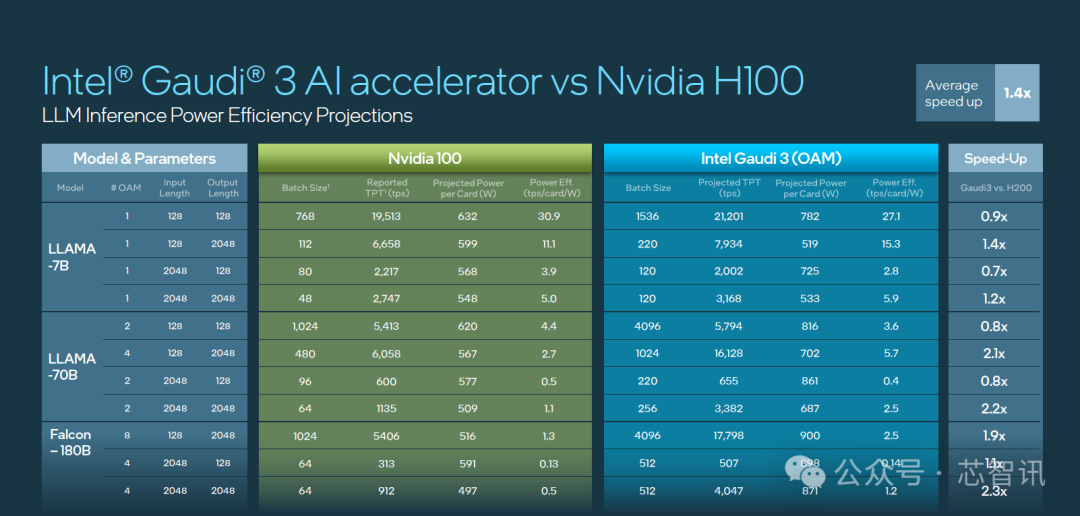
从具体的芯片性能方面来看,Theregister的报道显示,Gaudi 3 的密集的浮点性能为1,835 teraFLOPS ,而英伟达则依靠稀疏性来实现其公布的4 petaFLOPS性能。考虑到这一点,Gaudi3 仅比 H100 慢了约 144 teraFLOPS,同时提供了更多的HBM内存容量。而在半精度(FP16/BF16)下,Gaudi 3 可以实现相同的1,835 teraFLOPS性能,使其比英伟达H100领先了1.85 倍,比AMD MI300X 领先了 1.4 倍。但是,Gaudi 3不支持稀疏性。
目前英伟达B200和AMD MI300X都配备了192GB HBM3e/HBM3,英伟达上代的H200也配备了141GB HBM3。显然,Gaudi 3在这方面是相对落后不少的,仅比H100多一些,但还是较旧的HBM2e,这也使得其在HBM内存带宽上仅有3.7 TBps,远低于英伟达H200的4.8 GBps 和 AMD MI300X的 5.3 TBps。