 2024-04-23
2024-04-23 阅读:1553
阅读:1553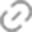 来源:曲速超为
来源:曲速超为在这个数字化飞速发展的时代,生成式AI正以其独特的魅力改变着我们的世界。从文字创作到图像设计,从音乐制作到视频剪辑,生成式AI以其强大的学习和生成能力,为我们带来了前所未有的创意体验。
生成式AI技术,包括自然语言生成、图像生成、音频生成、视频生成,生成式AI是指一类能够生成自然语言的AI模型,它们通过学习大量数据和语言规律,掌握语言的内在结构和语义关系,进而生成新的、合理的语言表达。
本文将在自然语言生成与图像生成内展开,着重分析GPT与图像生成的区别与联系。
两者概念
自然语言生成,简单来说就是让计算机理解、分析、生成人类语言的技术。它研究的是如何实现人与计算机之间如何用自然语言进行有效通信的各种理论与方法。
图像生成是指通过计算机算法和模型生成新的图像,这些图像可能是完全虚构的、艺术创作的、或者是根据现有图像进行修改和增强的。
自然语言处理模型——GPT
GPT这个词大家肯定都不陌生。
在自然语言处理中,Generative Pre-trained Transformer(GPT)系列是由OpenAI开发的一种基于Transformer的大规模自然语言模型。GPT模型采用了自监督学习的方式,首先在大量的无标签文本数据上进行预训练,然后在特定任务的数据上进行微调。这一系列的模型可以在非常复杂的NLP任务中取得非常惊艳的效果,例如文章生成,代码生成,机器翻译等。
GPT模型的优点在于,由于其预训练-微调的训练策略,它可以有效地利用大量的无标签数据进行学习,并且可以轻松地适应各种不同的任务。此外,由于其基于Transformer的结构,它可以并行处理输入序列中的所有单词,比基于循环神经网络的模型更高效。
GPT从出世到现在总共演进了五个版本:
GPT-1:在2018年,人工智能领域迎来了一场革命性的突破——GPT-1的发布。这款基于Transformer架构的单项语言模型,凭借其1.17亿参数和强大的预训练能力,改变了我们与机器的交互方式。GPT-1从海量互联网文本数据中汲取智慧,在初始阶段的能力相对单一,但通过在特定数据集上的微调,GPT-1能够逐渐适应各种复杂场景,从简单的文本生成到复杂的对话交互,都展现出惊人的潜力和应用价值。
GPT-2:作为GPT-1的改进版本,GPT-2凭借其庞大的模型规模和预训练参数数量,展现了前所未有的语言生成能力,拥有高达15亿的参数,远超其前身,使得模型在理解和学习语言规则方面更加出色。这种强大的模型规模保证了GPT-2能够产生更加流畅、自然的语言输出,无论是对话、文章还是其他文本形式,都能够轻松应对。
GPT-3:2020年诞生,凭借其1750亿个参数的庞大规模,成为GPT系列中最强大的一员。它不仅拥有卓越的语言处理能力,还具备零样本学习的独特能力,为解决各种类比问题提供了全新的思路。
GPT-3.5:2022年,OpenAI的预训练语言模型之路,又出现了颠覆式的迭代,产生了技术路线上的又一次方向性变化。在人工标注训练数据的基础上,再使用强化学习来增强预训练模型的能力。ChatGPT会承认错误、会修改自己的答复,这正是因为它具备从人类的反馈中强化学习并重新思考的能力。
GPT-4:2023年,OpenAI推出了GPT-4,这是目前最大规模的GPT模型,预训练了100万亿个参数。GPT-4使用了树型推理来完成建模,这使得GPT-4更加稳定、精确、高效,能够有效地解决复杂的NLP任务。
GPT这种基于深度学习的自然语言处理模型,不仅精通语言生成,还广泛涉足机器翻译、文本分类、问答系统等多个领域。GPT的魔法在于其深度学习能力,它能从海量的文本数据中洞察语言模式,生成富有逻辑、情感饱满的文本。无论是智能助手还是聊天机器人,GPT都在以其独特的方式,让语言交流变得更加自然、流畅。
图像生成
人工智能生成图像的技术主要包括基于规则、生成对抗网络(GANs)、变分自编码器(VAEs)、扩散生成模型(Diffusion)等几种。
图像生成主要分为无条件生成与有条件生成,而有条件生成中又有好几类,包括类别条件生成、文本条件生成、位置条件、图像扩充、图像内编辑、图像内文字生成、多种条件生成等。
从2022年下半年开始,Midjourney、Stable Diffusion等应用的诞生,让我们见证了文字与图像之间的奇妙转换,尤其在Stable Diffusion模型的开源将这一领域带到了新的高度。
那么就以Stable Diffusion为例来聊一聊图像生成:
2022年,主流模型Diffusion Model(扩散模型)爆火,它不仅可以生成图像,也可以生成视频、音频。Stable Diffusion图片生成的核心是Diffusion Model,它就是通过不停去除噪音期望获得好结果的生成模型。
在Stable Diffusion之前有Latent Diffusion,而后Stalibity AI改进了Latent Diffusion,新模型就是Stable Diffusion。
Stable Diffusion工作机制:(1)输入提示词;(2)对比、解析提示词;(3)UNet + Scheduler在信息(潜)空间中逐步处理/扩散信息;(4)图像解码器(使用处理过的信息矩阵绘制最终图像的解码器);(5)生成图片;

CLIP(大规模预训练图文表征模型):文本、图像编码器的组合,使用编码器对数据进行编码,将文本输入转换为机器可以理解的形式。
如下图为CLIP的模型结构图。在Stable Diffusion中,CLIP的文本编码器部分被用来将文本输入转换为一系列的特征向量,不断更新,后续编码器对图像和文本编码得到的嵌入会逐渐相似,最终生成一个嵌入向量。
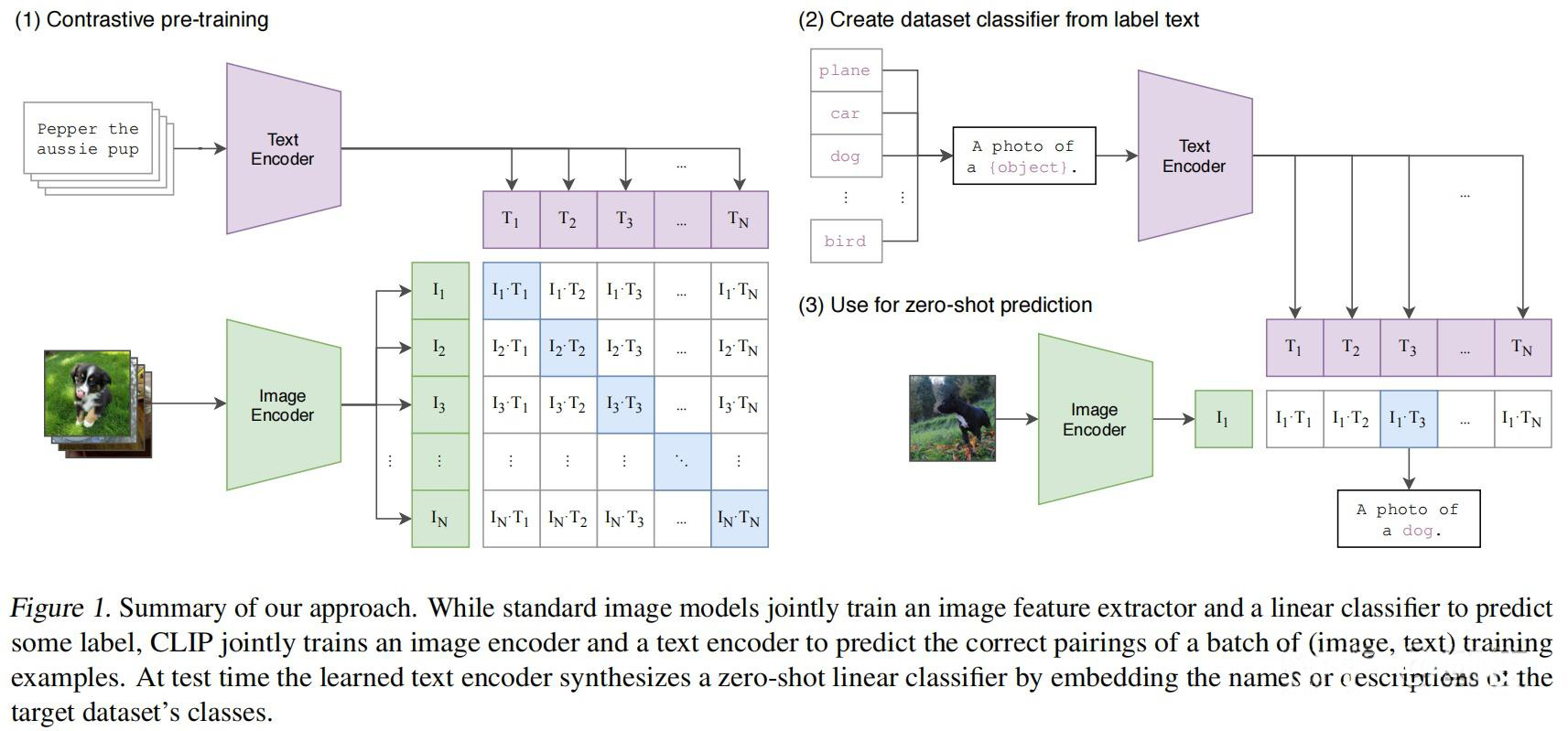
Diffusion:研究人员对图片加噪点,让图片逐渐变成纯噪点图;再让AI学习这个过程的逆过程,也就是如何从一张噪点图得到一张有信息的高清图。

整个Diffusion过程包含多个steps,其中每个step都是基于输入的latents矩阵进行操作,并生成另一个latents矩阵以更好地贴合输入的文本和从模型图像集中获取的视觉信息。
在完成所有去噪步骤后,StableDiffusion使用Decoder的神经网络将图像放大为高分辨率图像,精炼的图像在文本的指导下完全去噪,生成的高分辨率图像应强烈符合文本提示。
再以Midjourney、DALLE 2、DALLE3简单说说:
Midjourney通过输入文本和参数,并使用大量在图像数据上训练出的机器学习(ML)算法来完成图像。Midjourney目前只能通过官方Discord上的Discord机器人使用,目前Midjourney+ChatGPT的模式更受到推崇,即使用ChatGPT来输出内容,用Midjourney来输出绘图,最后进行整合。
DALLE 2通过一段文本描述生成图像,其使用超过100个亿参数的GPT-3转化器模型,能够解释自然语言输入并生成相应的图像。它由两部分组成——将用户输入转换为图像的表示(Prior),然后将这种表示转换为实际的照片(Decoder)。
DALLE3是OpenAI在2023年9月份发布的一个文生图模型,与上一代模型 DALLE2最大的区别在于,它可以利用ChatGPT生成提示,它原生构建在ChatGPT上,用ChatGPT来创建、优化和拓展prompt,大大提高用户效率。DALLE3相比DALLE2更能理解细微差别和细节,让用户更加轻松地将自己的想法转化为非常准确、炸裂的图像,并且OpenAI表示DALLE3拒绝生成在世艺术家风格的图片。
输入:“An expressive oil painting of a basketball player dunking, depicted as an explosion of a nebula.”
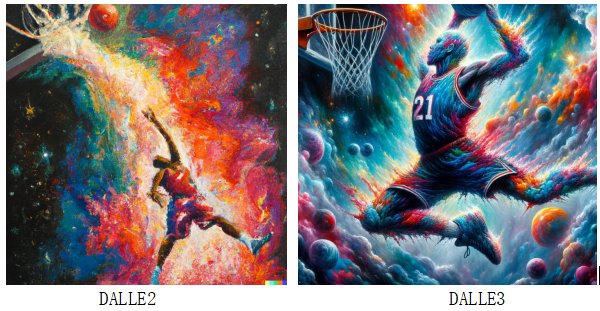
与左侧图片相比,显然右侧DALLE3生成图片中的细节描绘与清晰明亮度都更好。
从DALLE3展示效果看在ChatGPT里直接使用,官网案例:
问:My 5 year old keeps talking about a“super-duper sunflower hedgehog”-what does it look like?
ChatGPT给出四张图片:

问:My daughter says its name is Larry.
Can I see more like this?
ChatGPT给出四张图片:

问:Can you show me Larry’s house?
ChatGPT给出了房子的图片:

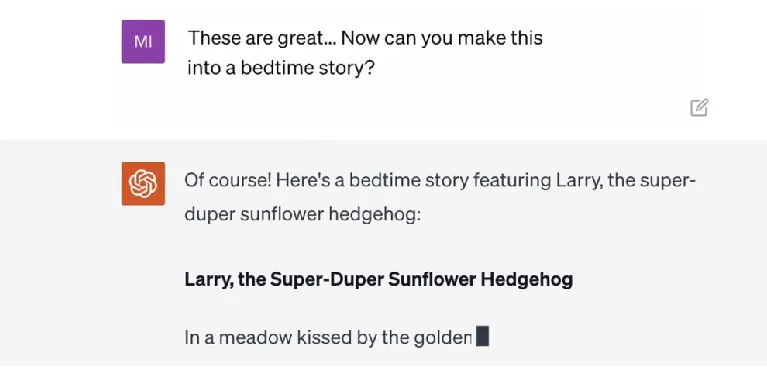
问:Larry is so cute!What makes him so super-duper?
ChatGPT开始写故事并给了一张图片:


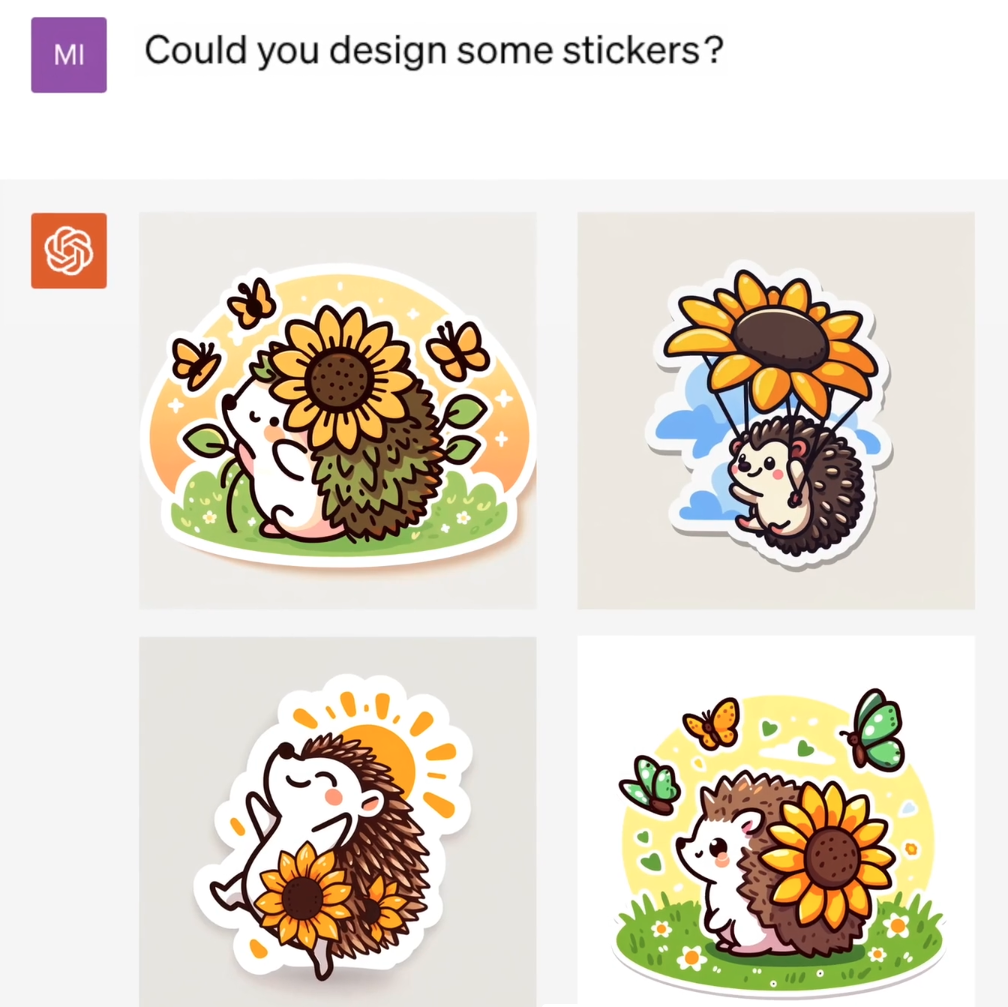
问:Could you design some stickers?
ChatGPT做出一些贴纸设计:
问:These are great...Now can you1 make these into a bedtime story?
ChatGPT开始写故事了:
问:When he is happily dreaming?
ChatGPT:Certainly!Here is an illustration of Larry,peacefully dreaming.
生成一张图片

从图片到故事,DALLE3与ChatGPT全部包揽,这意味着可以直接在极少时间内完成一本电子书籍。
目前,DALLE3已可以在GPT-4中体验了,还有如MidTool等,将GPT-4与DALLE3的功能结合起来,在其平台上,可以通过GPT-4模式利用DALLE3的能力来创作独特的作品。
从四者来看,DALLE2、DALLE3、Stable Diffusion、Midjourney相比,DALLE2其输出结果相比Stable Diffusion与Midjourney更加成熟,但于DALLE3逊色不少;DALLE3不需要自己掌握复杂的prompt编写知识,使用门槛更低;Midjourney更加艺术风格,全程都在Discord机器人上运作,所以看起来更像一幅画;Stable Diffusion优势在于开源模型,人人都可以使用,且可以生成充满细节的作品;
类似DALLE2、DALLE3、Midjourney、Stable Diffusion等同属文本生成图像领域的AI模型,其中扩散模型不仅可以用来生成图片,还可以生成视频,如Sora也是一个基于扩散过程构建的模型,并且结合Diffusion模型和GPT系列采用的Transformer构架,实现了一种创新融合。另外,Sora不仅可以根据文本生成视频,也可以直接输入图片或者视频,对图片和视频进行编辑调整。随着时间推移与科技发展,扩散模型也逐渐从图像、音频生成领域跃迁到自然语言生成领域的广阔天地,展现出巨大的潜力与应用价值。
本文简述了GPT与图像生成之间的区别与联系,从目前来看,AI工具的组合使用总能给人带来无与伦比的惊喜,无论是现在的ChatGPT+Stable Diffusion、ChatGPT+Midjourny、ChatGPT+DALLE3等,亦或是未来崛起的新的组合,ChatGPT+AI的使用必将会是巨大的市场,掀起一番新的浪潮。
参考资料: [1]https://www.cnblogs.com/AliceYing/p/14801518.html [2]https://mp.weixin.qq.com/s/VwDreFLAJtChU5n2CxZDPw [3]https://mp.weixin.qq.com/s/bNJZNEt7ftWCk5J0NwNz0A [4]https://jalammar.github.io/illustrated-stable-diffusion/ [5]https://baijiahao.baidu.com/s?id=1769636468615416451 [6]https://zhuanlan.zhihu.com/p/629914637 [7]https://blog.csdn.net/jiaoyangwm/article/details/129439761 [8]https://blog.csdn.net/weixin_45225032/article/details/136748267 [9]https://mp.weixin.qq.com/s/-UuAVPLqcZtexYObXJutcg